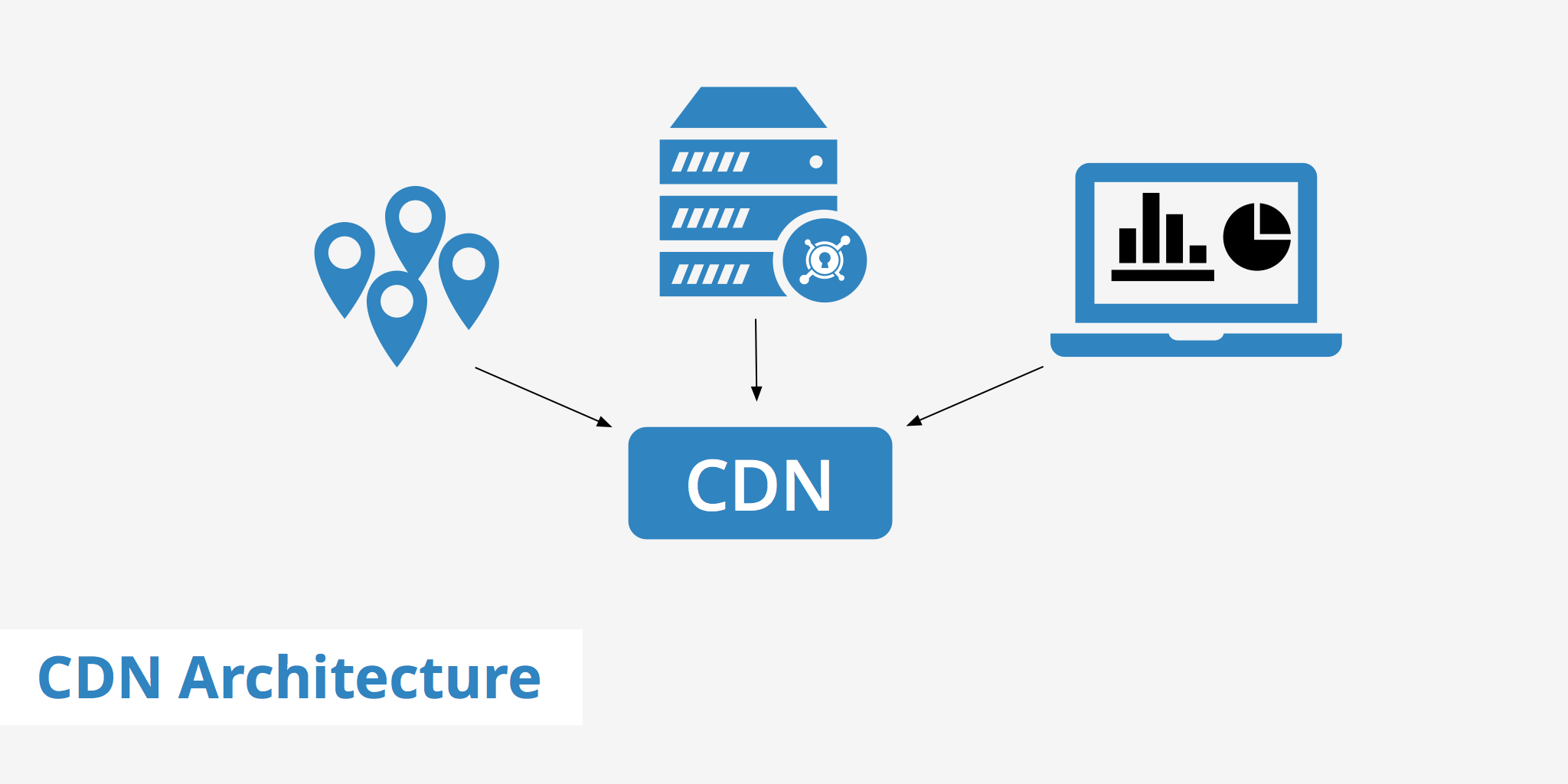
CDN和DNS
DNS 域名系统(Domain Name System),提供了主机名到 IP 地址转换的目录服务。 严格来说,DNS 具有两层含义: 由分层的 DNS 服务器实现的分布式数据库 查询分布式数据库的应用层协议,DNS协议使用 UDP,端口号 53 除了主机名到 IP 地址转换,DNS 还提供了其他服务: 主机别名:主机可以拥有多个主机名(一个规范主机名,多个别名),DNS 服务可以获取别名对应的 IP 和规范主机名 邮件服务器别名:和主机别名相同,邮件服务器也可以拥有别名便于记忆 负载分配:一个规范主机名可以对应多台服务器(多个IP),DNS 可以在这些 IP 地址集合中循环分配负载 域名层次 DNS 也代指由分层的 DNS 服务器实现的分布式数据库,这些 DNS 服务器,它们以层次方式组织并分布在全世界范围 DNS 服务器存储着主机到 IP 的映射,这些映射分布在所有的 DNS 服务器上,每一台都仅存储一部分的映射。 DNS 服务器在层次上分为三种: 根 DNS 服务器:根服务器遍及全球,根服务器提供的是 TLD 服务器的 IP 顶级域服务器(TLD):每个顶级域都有对 ...
UDP和TCP的多路复用和分解
运输层的作用 运输层将网络层在两个端系统之间的交付扩展到了运行在两个端系统上的应用进程之间的交付。 或者说运输层的协议为运行在不同主机上的应用进程提供了逻辑通信的能力。 因特网中的运输层协议有两种:UDP(用户数据报协议) 和 TCP(传输控制协议) 应用进程和运输层之间不会直接打交道,而是通过套接字来进行数据的传输,所以当运输层收到另一个端系统的某个应用进程发来的数据时,会将该数据交给上层对应的套接字,而非应用进程。 多路复用和分解 一台主机上会运行很多的应用进程,每个应用进程又可能会有一个或多个套接字,所以套接字需要有唯一的标识符来让运输层可以实现准确的交付。 多路分解: 运输层将报文段中的数据交付到正确的套接字的工作 多路复用: 运输层从上层不同的套接字收集数据并生成报文段,接着将报文段传递到网络层 实现多路分解和复用的要求: 套接字有唯一的标识符 每个报文字段有特殊字段(目的端口号、源端口号)来指示该报文字段所要交付的套接字 端口 端口号是一个 16 bit 的数,大小在 0 ~ 65535 之间。 0 ~ 1023 号端口被称为周知端口号,也就是说它们是给特定应用层 ...

NodeJS多进程
多进程 通过 child_process 模块即可创建多进程,被创建的进程称之为子进程,创建进程的进程称之为父进程。 多进程的意义在于可以充分利用计算机的 CPU 资源,早期的 Node 没有提供创建线程的方式,只有通过创建多个子进程来充分利用多核 CPU。 相比于多线程,虽然线程更加轻量,但是一个进程崩溃并不会影响另一个,而一个线程崩溃则整个进程都会崩溃,这对于服务器来说是不可接受的,所以一般都会使用 pm2 等工具部署,因为提供了守护进程用于守护 Node 进程。 如果使用子进程,尽量使用 commonjs 模块而不是 ES 模块,具体的看 issue 创建子进程 child_process 提供了同步和异步两种方式创建子进程,一般都是使用异步的方式创建: exec:创建一个子进程(shell)执行命令,通过回调(子进程退出时调用)可以获取 shell 的输出 spawn:创建一个子进程(shell)执行命令,但是没有回调去获取输出 execFile:创建一个子进程执行可执行文件,如果是 js 文件则文件开头必须有 #!/user/bin/env node fork:创建一个 ...
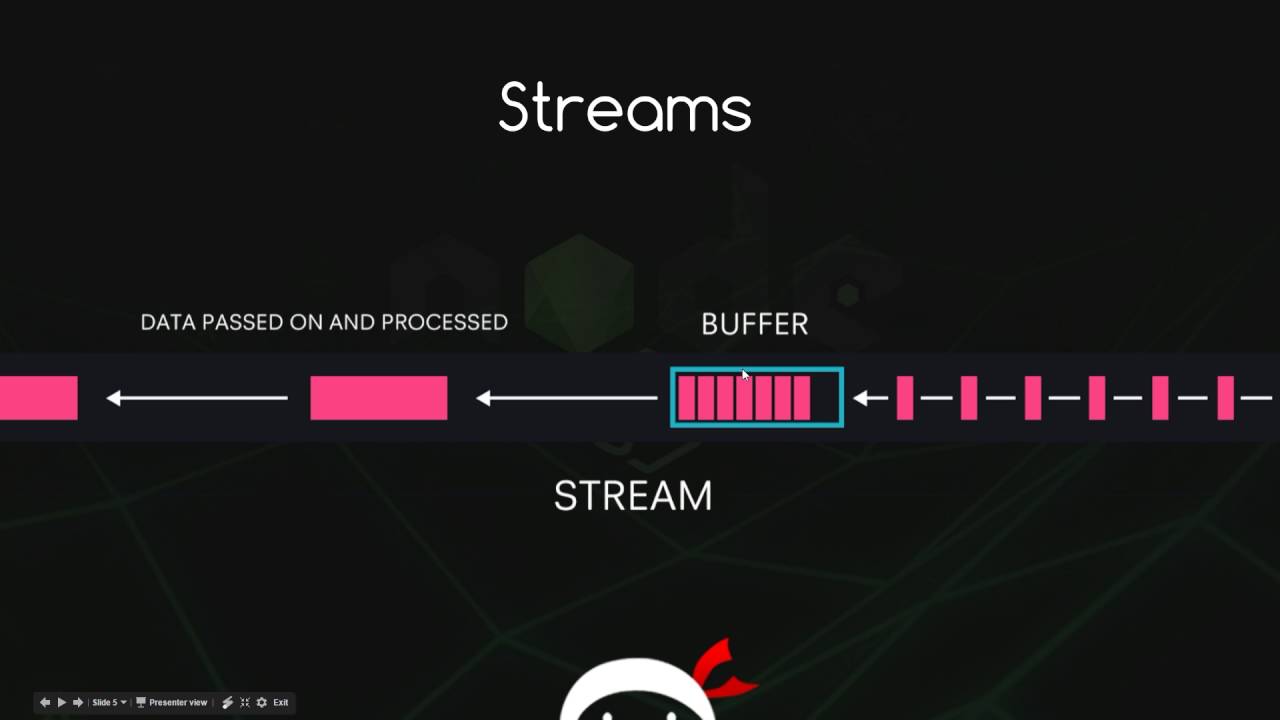
NodeJS中的流
流的意义 流的意义是我们可以不用将资源全部读入内存而是读一点消费一点,具有非常多的优点和用处。 Node 的 stream 模块提供了用于构建流接口的对象,但不提供某种流的具体实现。 stream api 的目的是为了限制数据的缓冲到可接受的程度,也就是读写速度不一致的源头与目的地不会压垮内存,而具体数据的处理(生产和消费)则需要自己实现。 也就是流在数据的生产和消费做了一层缓存,当读取流的时候读取的太慢则告知我们生成数据的速度就要降低,当将流从内存中写出时写的太快就要我们降低写的速度。 流的类型 Node 中共有四种类型的流: 可读流:对应的是 stream.Readable 类型 可写流:对应的是 stream.Writable 类型 双工流:对应的是 stream.Duplex 类型 转换流:对应的是 stream.Transform 类型 其中最重要的就是可读流和可写流;双工流存无非就是一个流既可读也可写,存在的原因是JavaScript中没有多继承;转换流本质就是一个双工流只不过在可读流和可写流进行数据转移时进行了数据的转换。 缓冲 既然流的目的是为了解决数据的两端 ...

HTTP/2特性
现状 自从 HTTP/1.1 发明以来,网站已经发生了很大的变化: 一个页面请求的消息大小从几 KB到几 MB 每个页面从小于10个资源,到多于100个资源 网站内容从文本为主到富媒体为主 对页面内容实时性高要求的应用越来越多 高延迟 虽然 HTTP/1.1 默认使用了长连接,但是随着带宽的提高以及网站资源数量的提升,延迟并没有显著下降 HTTP/1.1 的缺点慢慢暴露出来: 同一连接同时只能在完成一个 HTTP 事务(请求/响应)才能处理下一个事务 即使使用管道网络,但由于服务器的响应是顺序的,存在队头阻塞的问题 浏览器对一个域名下的并发连接有限(TCP 连接),Chrome 中同域名下资源加载的最大并发连接数为 6 需要重复的传输一些体积巨大的 HTTP 头部,例如用于维护用户状态的 cookie 不支持服务器的消息推送 HTTP/1.1 主要的问题就是并发度不够,在单个连接上串行的请求,没有充分的利用带宽,使得随着带宽的增加,延迟并没有显著下降 性能优化 为了提高网站的性能,在 HTTP/1.1 下所做的一些努力: 雪碧图,将许多张小图片放到一张大图片中,较少请求 ...

Web Worker
工作者线程 Web Worker 赋予了浏览器中的 JavaScript 多线程并发执行任务的能力。 传统的多线程模型(例如:POSIX 线程或者 Java 线程)不适合 JavaScript,因为像 DOM 这样的 API 会出现问题。 而这也正是工作者线程的价值所在:允许把主线程的工作转嫁给独立的实体,而不会改变现有的单线程模型。 Web 工作者线程规范中定义了三种主要的工作者线程: 专用工作者线程:通常简称为Web Worker,脚本可以单独创建一个 JavaScript 线程执行委托的任务 共享工作者线程:与专用工作者线程非常相似,主要区别是共享工作者线程可以被多个不同的上下文使用 服务工作者线:与专用工作者线程和共享工作者线程截然不同。它的主要用途是拦截、重定向和修改页面发出的请求 专用工作者线程 专用工作者线程可以称为后台脚本,JavaScript 线程的各个方面,包括生命周期管理、代码路径和输入/输出,都由初始化线程时提供的脚本来控制。 创建 通过 Worker 构造函数创建专用 Worker 线程,构造函数返回一个 Worker 实例,通过该实例可 ...

二叉堆
堆 在队列中,调度程序反复提取队列中第一个作业并运行,因为实际情况中某些时间较短的任务将等待很长时间才能结束,或者某些不短小,但具有重要性的作业,同样应当具有优先权。堆即为解决此类问题设计的一种数据结构。 堆可以实现优先队列(priority queue),有地方发也被称为优先队列,尽管名为优先队列,但堆并不是队列。 堆也是一种树状的数据结构,常见的堆实现: 二叉堆 多叉堆 索引堆 …… 基本接口 123456789interface Heap<T> { size: number; isEmpty(): boolean; clear(): void; add(ele: T): void; peek(): T | null; removeTop(): T | null; replace(ele: T): T | null} 二叉堆 堆的一个经典的实现是完全二叉树,这样实现的堆成为二叉堆。由于是完全二叉树,可以利用数组来作为底层实现的数据结构。 和二叉树类似,任意一个节点的子堆也是一个二叉堆,二叉堆的子 ...

Web文件处理
Blob Blob 表示一个不可变、原始数据的类文件对象,是 JavaScript 对不可修改二进制数据的封装类型。 包含字符串的数组、ArrayBuffers、ArrayBufferViews,甚至其他 Blob 都可以用来创建 blob 对象 构造函数 1new Blob(blobParts[, options]) blobParts:ArrayBuffer, ArrayBufferView, Blob, string 等构成的数组,这些都是 blob 的内容 options: type:默认值为 "",内容的MIME类型 endings:用于指定包含行结束符 \n 的字符串如何被写入,默认值为 "transparent" native:行结束符会被更改为适合宿主操作系统文件系统的换行符 transparent:保持blob中保存的结束符不变 实例对象 Blob 对象具有两个只读属性: size:数据大小 type:数据的 MIME 类型 Blob 的实例方法: slice([start[, end[, conte ...


